AReno documentation¶
Local post-training and serving
Train and serve local LLMs with one CUDA-native loop.
AReno keeps rollout, reward scoring, inference, optimizer steps, and checkpoint I/O in one compact engine for SFT, DPO, GSPO, GRPO, PPO, and agentic RL workflows.
Start¶
Install
Build against your CUDA PyTorch environment.
pip install psutil
pip install flash-linear-attention
pip install -e . --no-build-isolationUse ARENO_BUILD_EXT=0 for metadata-only docs or package checks on CPU-only machines.
Check
Verify the local runtime before training.
areno check
areno env --jsonareno check reports common CUDA, PyTorch, extension, and platform setup issues with next steps.
flash-attn is optional unless you use the default --attn-backend flash
path. Use --attn-backend native when you want to run without FlashAttention
or when the local GPU is unsupported by FlashAttention.
Core workflows¶
Run SFT, DPO, GSPO, GRPO, or PPO from the CLI with dataset loading, rollout, reward scoring, and checkpoint saving in one loop.
ServeStart an OpenAI-compatible chat-completions server backed by the local AReno inference engine.
CustomizeUse from areno import Trainer for custom rollout, reward, loss, and checkpoint loops.
Review the checkpoint families currently supported by AReno model adapters.
Training
Run a small GSPO smoke task.
areno train \
--ckpt Qwen/Qwen3-0.6B \
--dataset-path gsm8k:main \
--dataset-loader-fn examples/math/dataset_loader.py \
--reward-fn-path examples/math/math_verify_reward.py \
--algo gspo \
--tp-size 1 \
--world-size 1 \
--batch-size 1Serving
Open a local chat-completions endpoint.
areno serve \
--model-path /path/to/model \
--tp-size 1 \
--world-size 1 \
--port 8000Training and serving require a CUDA-capable NVIDIA GPU. CPU-only machines can run docs, packaging checks, and lightweight CPU tests, but cannot run the AReno training or serving engine.
Agentic rollout¶
Agentic RL
Collect trajectories through a local OpenAI-compatible proxy.
Agent functions call the local server, return explicit trajectory turns, and let AReno convert responses into completions, tokens, logprobs, rewards, and loss masks.
areno train \
--agent-fn examples/agentic/tictactoe/run_agent.py \
--reward-fn-path examples/agentic/tictactoe/reward.py \
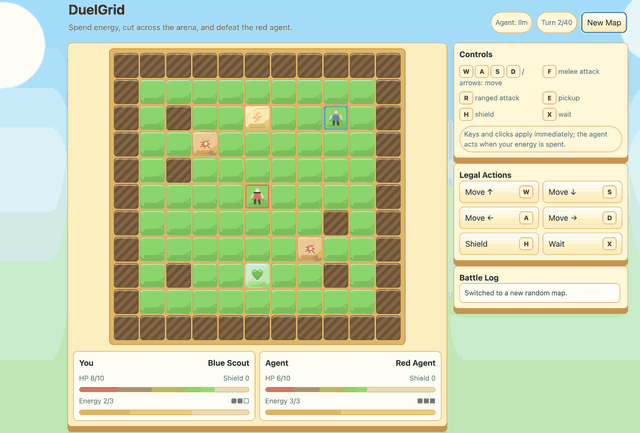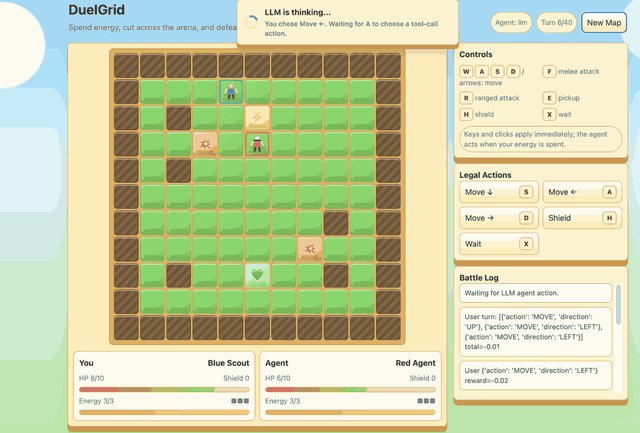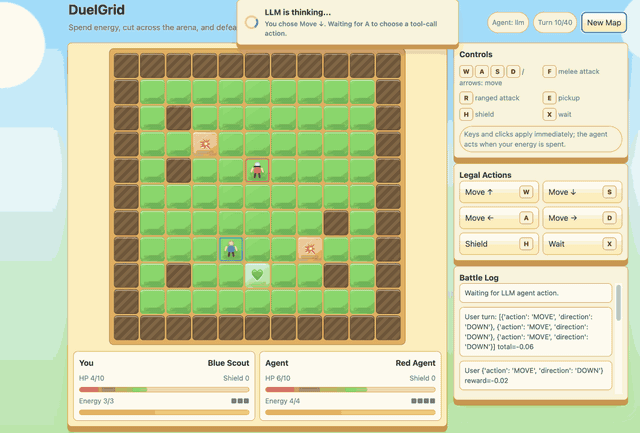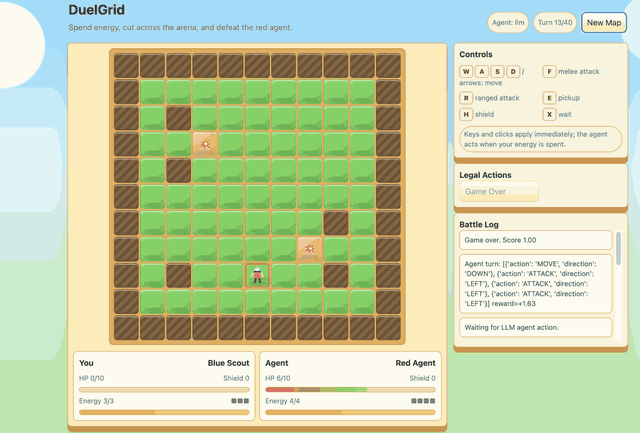
--algo gspoDuelGrid is a browser-game demo with multi-action turns. Before GSPO/RLVR post-training, Gemma-E2B-it often moves back and forth without progress. After training, it learns to collect pickups, chase the user, attack when in range, and avoid trap tiles.
Train before |
Reward |
Train after |
|---|---|---|
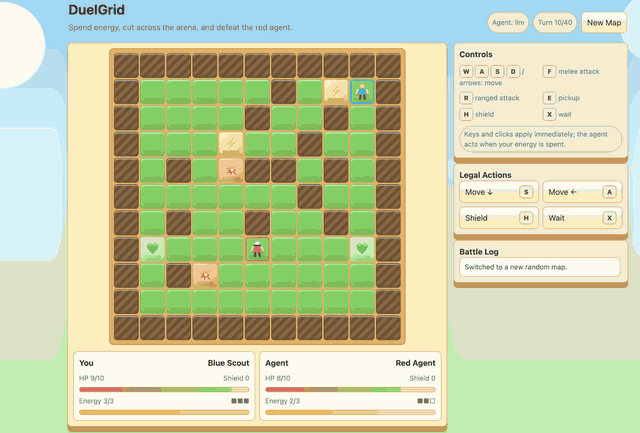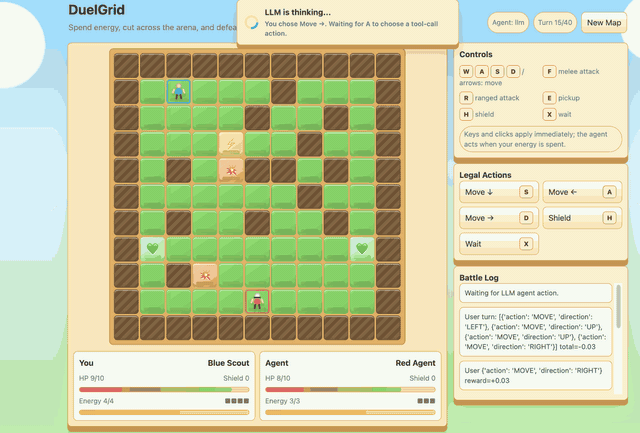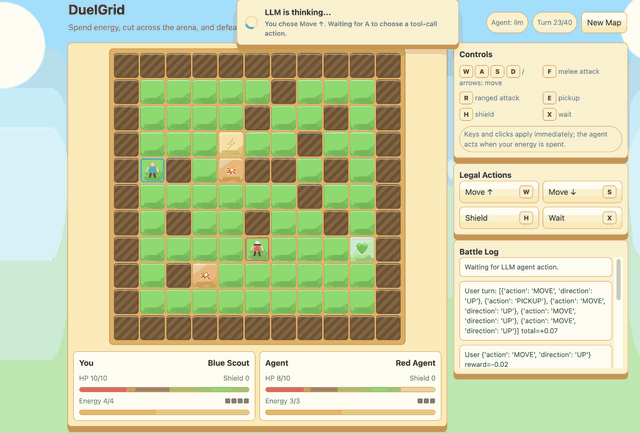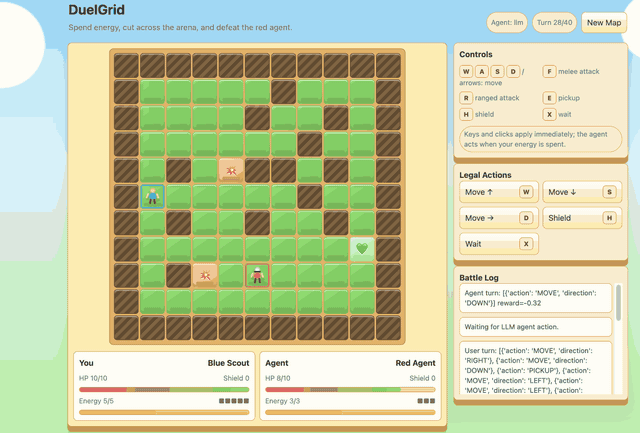
|
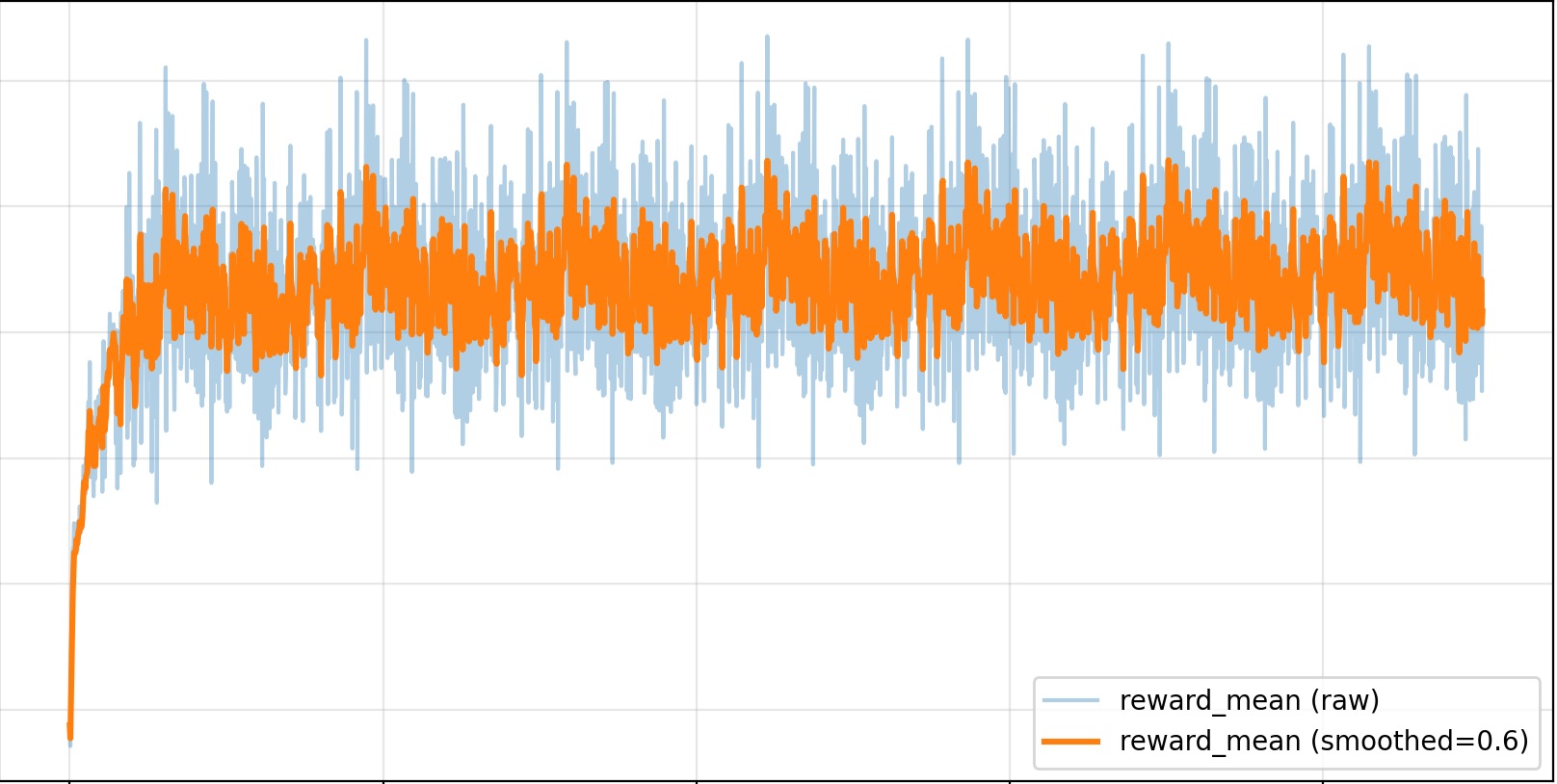
|
|
See examples/agentic/duelgrid for the rule engine, fixed-path dataset
loader, reward function, OpenAI-compatible agent, and browser UI.
What AReno owns¶
Fused CUDA paths in areno_accel for runtime hot paths.
Tensor-parallel workers, KV/cache layout, CUDA graph support, rollout state, scoring, optimizer steps, and checkpoint I/O.
SFT, DPO, GSPO, GRPO, PPO, and agentic rollouts implemented inside the project rather than delegated to a separate trainer framework.
Hugging Face-compatible load/save adapters for supported model families.